正则表达式
正则表达式
一、语法与元字符
1. 基本语法与元字符
基本语法与元字符

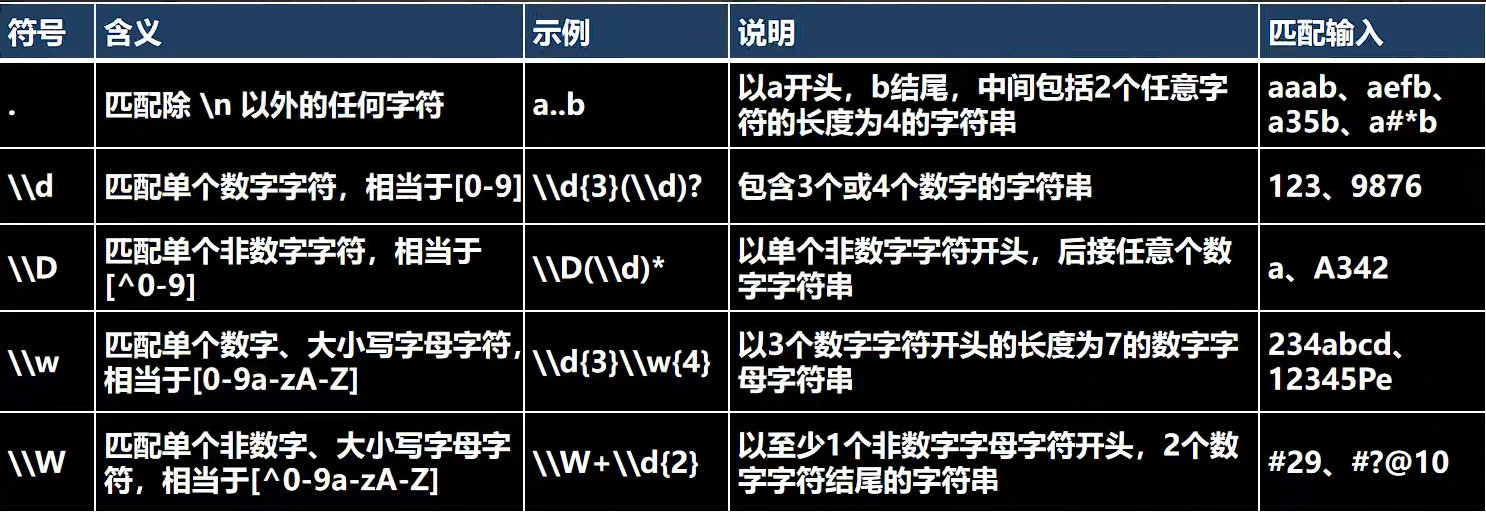
\\s:匹配空白字符\\S:与\\s取反,匹配任意非空白字符.:匹配除换行符外的所有字符(Java中换行符为\n)(?i)忽略大小写a(?i)bc对bc忽略大小写a((?i)b)c对b忽略大小写
1 | |
|:选择匹配符ab|cd:匹配ab或者cd
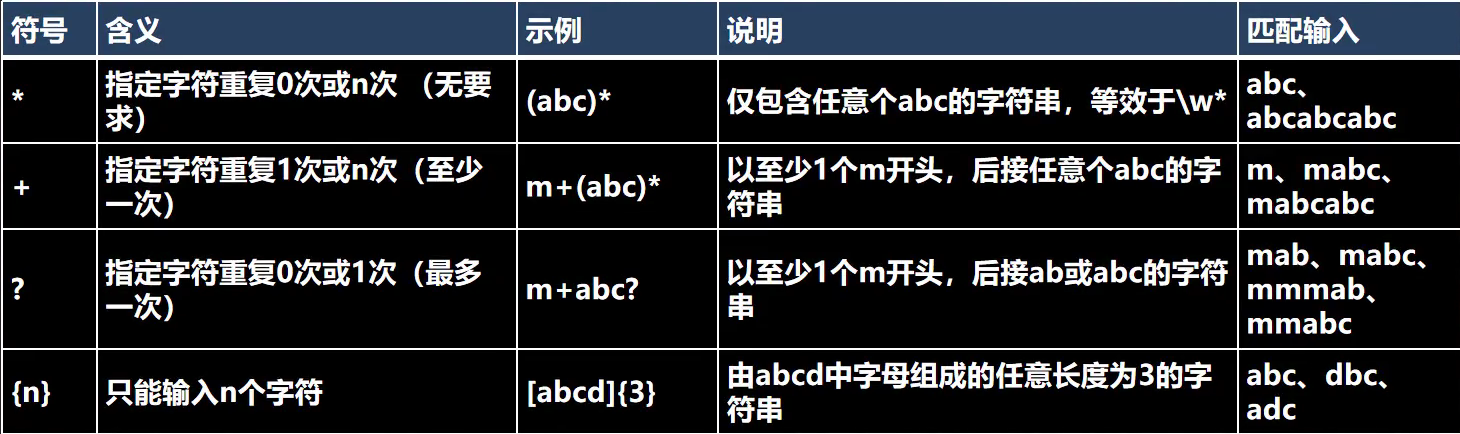
2. 限定符
用于指定其之前的字符或组合连续出现的次数

3. 定位符
规定字符在字符串中的位置

\\b:这里边界指一个单词的结尾 若字符串中有空格,则空格作为分隔符分隔单词\\B:指每个单词的开头或中间
4. 捕获分组

(pattern)1
String regex = "([0-9]{2})(\\d)(\\d)";(?<name>pattern)1
String regex = "(?<g1>[0-9]{2})(?<g2>\\d)(?<g3>\\d)";
5.非捕获分组

(?:pattern)1
2
3
4String str = "jack=10 bob=19 tom=10";
String regex = "\\w*=(?:10)";
//得到 jack=10 tom=10(?=pattern)1
2String regex = "\\w*=(?=10)";
//得到 jack= tom=(?!pattern)1
2String regex = "\\w*=(?!10)";
//得到 bob=
6.反向引用
内部:在正则表达式中引用
外部:在其他方法中引用
\\n内部反向引用- 表示正则式中第n组匹配的值
- **n ** 表示一个捕获分组,在group中的组序号
1 | |
$n外部反向引用1
2
3
4Pattern pattern1 = Pattern.compile("(.)\\1+");
Matcher matcher1 = pattern1.matcher(s);
// 使用外部反向引用,$1 表示正则式中的第一个分组捕获的值
String res = matcher1.replaceAll("$1");
7. 贪婪匹配与懒惰匹配
正则表达式中默认为贪婪匹配
懒惰匹配 -> 尽可能少的匹配
默认为贪婪匹配 -> 尽可能多的匹配

1 | |
三、Java中常用的三个类
1. Pattern
matches(regex , url)整体匹配,只能返回Boolean1
boolean isMatch = Pattern.matches(regex, url);compile(regex)返回正则表达式对象 能用于生成匹配器对象 传入匹配器的字符串中只要有符合的就能匹配,能输出结果值1
2
3
4
5
6Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(str);
while (matcher.find()){
System.out.println(matcher.group(0));
}
2. Matcher
matcher 是一个匹配对象


3. String
replaceAll(regex , s)1
2String str = "jdk1.3dadasdasdjdk1.4asdas3423dfsjdk1.5";
String res = str.replaceAll("jdk\\d+\\.\\d+", "JDK");matches(regex)整体匹配split(regex)1
2
3String str2 = "AAA#CCC&AAA~CCC12GGG";
//用#~&数字分割字符串
str2.split("[#&~]|\\d+");
二、实际应用
1. 判断汉字
注意汉字的编码范围在
\u0391-\uffe5,**\u4e00-\u9fa5**
1 | |
2. 判断邮编
以1开头的六位数字
1 | |
3. 判断URL
^((http)s?://)?([\\w-]+\\.)+[a-zA-Z0-9]+((/[\\w-#]+)+\\?([\\w-]+=[\\w-]+&?)*)?$
``^((http)s?://)?`
- s 可有可无
- https:// 可有可无
([\\w-]+\\.)+- 可能存在多级域名
- abc.dc.aaa.com.cn
- 可能存在多级域名
[a-zA-Z0-9]+- 域名结尾
((/[\\w-#]+)+\\?([\\w-]+=[\\w-]+&?)*)?$(/[\\w-#]+)+- 可能存在所层路径
- /video/aa/bb
- 可能存在所层路径
\\?- 路径结尾带有参数
([\\w-]+=[\\w-]+&?)*[\\w-]+参数名由这些字符组成=名与值之间用 = 相连[\\w-]+参数值由这些字符组成&?每对参数之间用 & 相连,若只有一对参数则无需&*参数可能有一对或多对
?$整个域名后的路径或值都可有可无 并都已存在的元素作为整个URL结尾
1 | |
4. 结巴问题
将 ‘’我我我….要要….吃吃吃吃..饭‘’ 变成 ”我要吃饭“
1 | |
5. 验证数字规范性
识别整数 , 小数,负数等
^[-+]?([1-9]\\d*|0)(\\.\\d+)?$[-+]?- 数字符号不一定存在
([1-9\\d*|0])- 数字以 1 开头
- 或以 0 开头的小数且只能由一个 0
(\\.\\d+)?- 数字的小数部分不一定存在